第12章:异常处理与恢复 Exception Handling and Recovery
为了使AI智能体能够在多样化的真实世界环境中可靠运行,它们必须能够应对不可预见的情况、错误和故障。正如人类能够适应意外的障碍一样,AI智能体需要具备强大的系统来检测问题、启动恢复程序,或者至少确保在失败时能够进行受控处理。这一基本需求构成了“异常处理与恢复模式”的基础。
该模式旨在开发异常耐用且具有弹性的智能体,使其能够在各种困难和异常情况下保持不间断的功能和操作完整性。它强调了主动准备和反应策略的重要性,以确保即使在面对挑战时也能持续运行。这种适应能力对于智能体在复杂且不可预测的环境中成功运作至关重要,从而最终提高其整体效率和可信度。
处理意外事件的能力确保了这些人工智能系统不仅智能,而且稳定可靠,从而增强了对其部署和性能的信心。集成全面的监控和诊断工具进一步强化了智能体快速识别和解决问题的能力,防止潜在的中断,确保在不断变化的条件下平稳运行。这些先进的系统对于维护人工智能操作的完整性和效率至关重要,增强了其应对复杂性和不可预测性的能力。
该模式有时可以结合反思机制使用。例如,如果初次尝试失败并引发异常,反思过程可以分析失败原因,并通过改进的方法(例如优化的提示)重新尝试任务,以解决错误。
异常处理与恢复模式概述
异常处理与恢复模式解决了AI智能体管理操作失败的需求。该模式包括预测潜在问题,例如工具错误或服务不可用,并制定缓解这些问题的策略。这些策略可能包括错误日志记录、重试、回退、降级处理和通知。此外,该模式强调恢复机制,例如状态回滚、诊断、自我纠正和升级,以恢复智能体的稳定运行。实施该模式可以增强AI智能体的可靠性和鲁棒性,使其能够在不可预测的环境中运行。实际应用的例子包括管理数据库错误的聊天机器人、处理金融错误的交易机器人以及解决设备故障的智能家居智能体。该模式确保智能体在面对复杂性和失败时仍能有效运行。
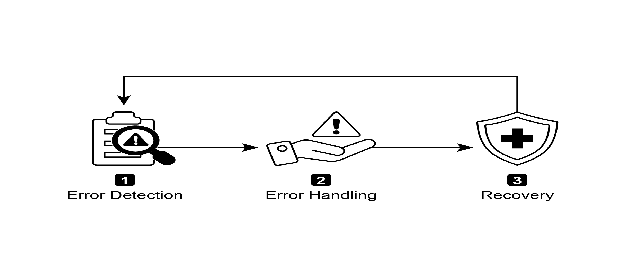
图1:AI智能体异常处理与恢复的关键组成部分
错误检测: 这包括在问题发生时仔细识别操作问题。这可能表现为无效或格式错误的工具输出、特定的 API 错误(如 404“未找到”或 500“内部服务器错误”代码)、服务或 API 响应时间异常延长,或者偏离预期格式的无意义或不连贯的响应。此外,还可以通过其他智能体或专门的监控系统实施监控,以实现更主动的异常检测,使系统能够在问题升级之前捕获潜在问题。
错误处理: 一旦检测到错误,制定一个经过深思熟虑的响应计划至关重要。这包括在日志中详细记录错误信息以便后续调试和分析(日志记录)。对于临时性错误,重新尝试操作或请求(有时稍作参数调整)可能是一种可行的策略(重试)。采用替代策略或方法(回退)可以确保某些功能得以维持。在无法立即完全恢复的情况下,智能体可以保持部分功能,以便至少提供一定的价值(优雅降级)。最后,对于需要人工干预或协作的情况,通知人类操作员或其他智能体可能是至关重要的(通知)。
恢复: 此阶段旨在将智能体或系统从错误中恢复到稳定且可操作的状态。这可能涉及撤销最近的更改或事务以消除错误的影响(状态回滚)。深入调查错误的原因对于防止错误的再次发生至关重要。通过自我纠正机制或重新规划过程调整智能体的计划、逻辑或参数,可能是避免未来发生相同错误所必需的。在复杂或严重的情况下,将问题委派给人类操作员或更高级别的系统(升级)可能是最佳的解决方案。
实施这种健壮的异常处理和恢复模式,可以将 AI 智能体从脆弱和不可靠的系统转变为能够在具有挑战性和高度不可预测的环境中有效且具有弹性的可靠组件。这确保了智能体能够维持功能,最大限度地减少停机时间,即使在面对意外问题时也能提供无缝且可靠的体验。
实际应用与使用场景
异常处理与恢复对于任何部署在现实世界中、无法保证完美条件的智能体来说都是至关重要的。
- 客户服务聊天机器人: 如果聊天机器人尝试访问客户数据库,而数据库暂时不可用,它不应该崩溃。相反,它应该检测到 API 错误,通知用户暂时性问题,可能建议稍后重试,或者将查询升级到人工智能体处理。
- 自动化金融交易: 交易机器人在尝试执行交易时可能遇到“资金不足”错误或“市场关闭”错误。它需要通过记录错误来处理这些异常,而不是反复尝试同样无效的交易,并可能通知用户或调整其策略。
- 智能家居自动化: 控制智能灯的智能体可能由于网络问题或设备故障而无法打开灯。它应该检测到此故障,尝试重试,如果仍然失败,则通知用户灯无法打开并建议手动干预。
- 数据处理智能体: 负责处理一批文档的智能体可能遇到损坏的文件。它应该跳过损坏的文件,记录错误,继续处理其他文件,并在结束时报告被跳过的文件,而不是停止整个处理过程。
- 网络爬虫智能体: 当网络爬虫智能体遇到 CAPTCHA、网站结构变化或服务器错误(例如 404 未找到、503 服务不可用)时,它需要优雅地处理这些情况。这可能包括暂停、使用智能体或报告失败的具体 URL。
- 机器人与制造业: 执行组装任务的机械臂可能由于对齐问题而未能拾取组件。它需要检测到此故障(例如,通过传感器反馈),尝试重新调整,重试拾取操作,如果问题持续存在,则通知人类操作员或切换到其他组件。
总之,这种模式是构建不仅智能而且在面对现实世界复杂性时可靠、弹性和用户友好的智能体的基础。
实战代码示例(ADK)
异常处理和恢复对于系统的稳健性和可靠性至关重要。例如,可以考虑一个智能体在工具调用失败时的响应。这类失败可能源于工具输入错误或工具依赖的外部服务出现问题。
from google.adk.agents import Agent, SequentialAgent
## Agent 1: 尝试使用主要工具。其目标明确且专注。
primary_handler = Agent(
name="primary_handler",
model="gemini-2.0-flash-exp",
instruction="""
您的任务是获取精确的位置信息。使用用户提供的地址调用 get_precise_location_info 工具。
""",
tools=[get_precise_location_info]
)
## Agent 2: 作为备用处理器,根据状态决定其动作。
fallback_handler = Agent(
name="fallback_handler",
model="gemini-2.0-flash-exp",
instruction="""
检查状态变量 state["primary_location_failed"] 以确定主要位置查询是否失败。
- 如果为 True,从用户的原始查询中提取城市信息并使用 get_general_area_info 工具。
- 如果为 False,不执行任何操作。
""",
tools=[get_general_area_info]
)
## Agent 3: 从状态中呈现最终结果。
response_agent = Agent(
name="response_agent",
model="gemini-2.0-flash-exp",
instruction="""
检查存储在 state["location_result"] 中的位置信息。清晰简洁地向用户呈现这些信息。
如果 state["location_result"] 不存在或为空,向用户道歉,说明无法检索到位置信息。
""",
tools=[] # 该智能体仅对最终状态进行推理。
)
## SequentialAgent 确保处理器按预定顺序运行。
robust_location_agent = SequentialAgent(
name="robust_location_agent",
sub_agents=[primary_handler, fallback_handler, response_agent]
)
这段代码使用 ADK 的 SequentialAgent 定义了一个稳健的位置信息检索系统,该系统包含三个子智能体。primary_handler 是第一个智能体,尝试使用 get_precise_location_info 工具获取精确的位置信息。fallback_handler 充当备份角色,通过检查状态变量来判断主要查询是否失败。如果主要查询失败,备用智能体会从用户的查询中提取城市信息并使用 get_general_area_info 工具。response_agent 是序列中的最后一个智能体,它检查存储在状态中的位置信息,并将最终结果呈现给用户。如果未找到任何位置信息,它会向用户道歉。SequentialAgent 确保这三个智能体按预定义顺序执行。该结构提供了一种分层的方法来进行位置信息检索。
概览
定义(What)
在现实环境中运行的 AI 智能体不可避免地会遇到意外情况、错误和系统故障。这些中断可能包括工具故障、网络问题以及无效数据,这些问题会威胁到智能体完成任务的能力。如果没有结构化的方法来处理这些问题,智能体可能会变得脆弱、不可靠,并在面对意外障碍时完全失效。这种不可靠性使得智能体难以在关键或复杂的应用场景中实现稳定运行。
设计意图(Why)
异常处理与恢复模式为构建稳健且具有弹性的 AI 智能体提供了标准化解决方案。它使智能体具备预测、管理和从操作故障中恢复的能力。该模式包括主动错误检测(例如监控工具输出和 API 响应)以及反应式处理策略(如记录诊断日志、重试临时故障或使用备用机制)。对于更严重的问题,它定义了恢复协议,包括恢复到稳定状态、通过调整计划进行自我修正,或将问题上报给人工操作员。这种系统化的方法确保智能体能够保持操作完整性,从失败中学习,并在不可预测的环境中可靠运行。
使用原则(Rule of Thumb)
在任何部署于动态、真实世界环境中的 AI 智能体中使用此模式,尤其是在可能出现系统故障、工具错误、网络问题或不可预测输入的情况下,并且操作可靠性是关键要求。
图解 (Visual Summary)
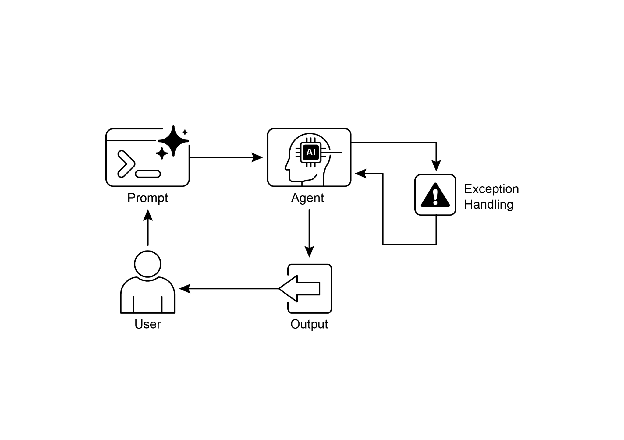
图 2:异常处理模式
关键要点
需要记住的核心内容:
- 异常处理与恢复是构建稳健可靠智能体的关键。
- 此模式包括错误检测、优雅处理错误以及实施恢复策略。
- 错误检测可以包括验证工具输出、检查 API 错误代码以及使用超时机制。
- 处理策略包括记录日志、重试、备用机制、优雅降级和通知。
- 恢复专注于通过诊断、自我修正或问题上报来恢复稳定操作。
- 此模式确保智能体即使在不可预测的真实世界环境中也能有效运行。
结论
本章探讨了异常处理与恢复模式,这是开发稳健可靠 AI 智能体的关键。该模式解决了 AI 智能体如何识别和管理意外问题、实施适当响应以及恢复到稳定操作状态的问题。本章讨论了该模式的各个方面,包括通过记录日志、重试和备用机制等方式检测和处理错误,以及恢复智能体或系统正常功能的策略。通过多个领域的实际应用,展示了异常处理与恢复模式在应对现实世界复杂性和潜在故障方面的相关性。这些应用表明,为 AI 智能体配备异常处理能力有助于提高其在动态环境中的可靠性和适应性。
参考文献
- McConnell, S. (2004). Code Complete (2nd ed.). Microsoft Press.
- Shi, Y., Pei, H., Feng, L., Zhang, Y., & Yao, D. (2024). Towards Fault Tolerance in Multi-Agent Reinforcement Learning. arXiv preprint arXiv:2412.00534.
- O'Neill, V. (2022). Improving Fault Tolerance and Reliability of Heterogeneous Multi-Agent IoT Systems Using Intelligence Transfer. Electronics, 11(17), 2724.