

循环工程(Loop Engineering)
二〇二六年六月二日的傍晚,旧金山。一场不对外开放的活动正在进行,主办方是身份认证创业公司 WorkOS,受邀的是城里一小撮写代码、投代码、谈论代码的人。台上坐着 Boris Cherny——Anthropic 旗下编程工具 Claude Code 的负责人——以及两位以打捞硅谷秘史为业的播客主持人。话题原本是寻常的:模型、产品、那种每隔几个月就要重新定义一次的"未来"。然后 Cherny 说了一句话,几天之内,它像一粒投进静水的石子,在工程师们的社交媒体上漾开了一圈又一圈。
"我已经不再给 Claude 写提示词了,"他说,"我让一堆循环跑着,由它们去给 Claude 写提示词、去琢磨该做什么。我的工作,是写循环。而这,是我们今年余下时间都会看到的转变。"
如果你不在这一行,这句话听上去几乎是无害的,甚至有点像绕口令。但对于在场的人——以及随后在网上转发它的成千上万人——它触到了某种正在松动的地基。在过去两年里,整个软件行业学会了一个新词:提示词工程(prompt engineering)。人们学习如何措辞,如何举例,如何把一个含糊的愿望翻译成机器能听懂的句子。出现了教程,出现了岗位,出现了"提示词工程师"这种半是玩笑半是认真的头衔。而现在,这个行业里最靠近一线的人之一站起来说:那个技能,那门刚刚学会的手艺,已经过时了。你不该再跟机器对话。你该去设计一套自己会对机器说话的系统。
五天后,六月七日,另一个名字加入进来。Peter Steinberger——一位以高产和直率著称的工程师,开源项目 OpenClaw 的作者,二月里刚刚加入 OpenAI——在 X 上发了一条几乎是宣言式的帖子:"这是你每月一次的提醒:你不该再给编程 agent 写提示词了。你该去设计那些替你给 agent 写提示词的循环。"
同一天,第三个声音把这一切收拢成了一个词。Addy Osmani,谷歌的工程师,一位长期写技术博客、在开发者中颇有号召力的人,发表了一篇题为《循环工程》(Loop Engineering)的文章。他没有发明这种做法——做法早就在车库里、在深夜的终端里悄悄生长——但他给它起了名字,搭了骨架。"循环工程,"他写道,"就是把'那个给 agent 写提示词的人'——也就是你自己——替换掉。你转而去设计那套替你做这件事的系统。这里的'循环',可以理解成一个递归的目标:你定义一个目的,然后 AI 不断迭代,直到完成。"
于是,在大约一周之内,一个术语诞生了。它还很年轻——年轻到这篇文章写下时,它的"年龄"用周来计算更合适。它没有经过同行评议,没有教科书定义,它栖身于博客、推文和带着商业导流意图的二手解读里。但它指向的东西是真实的。要理解它真实在哪里,得先把时间往回拨。
古老的概念,换了身新衣
任何在这一行待得够久的人,听到"循环"这个词都会有点会心一笑。循环是程序员最古老的伙伴之一。while、for、do...until——让机器把同一件事做上一千遍,本就是计算的本义。所以当工程师说"我的工作是写循环"时,有一层近乎黑色幽默的意味:人类绕了一大圈,从亲手写循环,到亲手写提示词,又回到了写循环。只不过这一次,循环里跑的不是数字的累加,而是一个会推理、会写代码、会犯错的智能体。
这里需要一个小心的澄清,因为"循环"这个词此刻正承载着两个不同的含义,混为一谈会让人彻底糊涂。第一个含义更古老,也更技术:所谓"agent 循环"或"反馈循环",指的是智能体自身的那个控制环——规划、行动、观察、反思、再行动。它的祖先是二〇二二年普林斯顿和谷歌的研究者提出的 ReAct 范式,把"推理"和"行动"交织在一起。这是机器内部的循环。而第二个含义,也就是六月这一周引爆的那个,说的是人的位置变了:人从循环里退出来,退到上面一层,去设计那套自动驱动机器的调度系统。一个是机器在转,一个是人在为机器的转动布局。(顺带一提,世上还真有一家叫"Loop Engineering"的公司,做的是电气设备,与此事毫无干系——这是搜索引擎时代的小小陷阱。)
如果你愿意把这条线索拉得更长,会发现这个念头一直在以不同的名字反复出现。二〇二四年初,一篇名为《用 AlphaCodium 生成代码:从提示词工程到流程工程》的论文,第一次给"为代码生成设计一套测试驱动、多阶段、反复迭代的流程"这件事起了个名字——流程工程(flow engineering)。它带着难得的硬数据:在一个验证集上,GPT-4 的准确率从单条精心设计的提示词的百分之十九,提升到了走完整套 AlphaCodium 流程后的百分之四十四,两倍多。这是"循环"思想第一次有了量化的底气。二〇二五年,"上下文工程"(context engineering)流行起来,关注的是该往模型的"上下文窗口"里塞什么,提示词工程就此降格成它的一个子集。同年夏天,一位叫 Geoffrey Huntley 的工程师写下了循环工程最朴素、最像民间偏方的原型——人称"拉尔夫循环"——其全部精髓不过是一行命令:把一份提示词文件反复喂给编程工具,无限循环,每一轮都用全新的上下文,把文件系统和版本控制当作机器的记忆。它丑陋,粗暴,却出奇地有效。
所以,当 Anthropic 和 OpenAI 的人在二〇二六年六月谈论"循环工程"时,他们并不是从虚空中召唤出一门新学科。他们是给一个已经生长了几年的实践,盖上了一个响亮的、便于传播的名字。对于一位需要做技术决策的管理者来说,看穿这一点至关重要:循环工程在很大程度上不是一门独立的新学问,而是另一个更扎实的概念——"框架工程"(harness engineering)——的上层封装,是在它之上加了一个定时器和一套自驱机制。
框架
要说清楚循环工程加了什么,得先说清楚它站在什么之上。这里最有说服力的心智模型来自 Thoughtworks 的 Birgitta Böckeler,她把它压缩成一个等式:Agent = 模型 + 框架(Agent = Model + Harness)。
模型是那个会思考的大脑,是 Claude 或 GPT。而"框架"是大脑之外的一切——是它伸出去触碰世界的手脚和神经。Böckeler 把框架进一步拆成两半。一半叫"前馈"(guides),是在 agent 行动之前给它的引导:项目约定文档、严格的类型系统、代码风格检查器。这些像是路标,告诉它该往哪走。另一半叫"传感器"(sensors),是让 agent 在行动之后观察到后果的东西:测试套件、运行时日志、持续集成的红灯绿灯。这些像是神经末梢,告诉它撞到了什么、做对了没有。
一位叫 Daniel Demmel 的实践者把这条进化链排成了一个清晰的阶梯:提示词工程,低于上下文工程,低于反馈循环工程,低于框架工程。每往上一级,人操心的东西就抽象一层。而循环工程,本质上就是在框架工程这套"感知—行动"的神经系统之上,又装了一个发条——让它不必等人按下启动键,自己就能转起来。
Osmani 在他的文章里,把一个能"无人值守"运转的循环拆成了六个零件,像拆解一台钟表。

- 第一是自动触发,定时的或由事件激发的,比如代码仓库里冒出一个新问题,循环就自己醒来。
- 第二是隔离的工作区,用版本控制的分支技术把同时干活的多个 agent 隔开,免得它们互相踩到对方的文件。
- 第三是技能沉淀,把项目的知识写进专门的文档,让后来的 agent 站在前人的肩上。
- 第四是连接器,让 agent 能伸手够到问题追踪系统、数据库、聊天工具。
- 第五,也是最精巧的一环,是"制造者/检查者"的分离——一个 agent 负责写,另一个独立的 agent 负责验,绝不让写代码的那个给自己的作业打分。
- 第六是记忆,把状态存在上下文窗口之外的某个地方,让循环跨越一次次会话,记得自己走到了哪里。
这六个零件里,藏着整个范式最要命的一个工程难题:循环什么时候算"做完了"?如果终止的条件是机器自己说了算,它要么会无限空转、把钱烧光,要么会自欺欺人地宣布胜利。所以真正讲究的做法,是让一个独立的小模型去判断"是否完成",而且判据必须是可被客观验证的——比如"所有测试通过且代码检查无误",而不是某个 agent 心满意足的一句"我觉得行了"。这个细节看似琐碎,却是整座大厦的承重墙。它把一个哲学问题——"我们怎么知道一件事真的做好了"——变成了一行可以执行的代码。
那些惊人的数字
如果循环工程只是一套优雅的工程哲学,它不会在一周内点燃整个行业。点燃它的,是数字——而且是惊人的数字。
最具体的一个故事来自 OpenAI 内部一支叫 Frontier 的团队,由工程师 Ryan Lopopolo 带领。他们用自家的编程工具 Codex,做了一件近乎挑衅的事:从二〇二五年八月底的第一次提交算起,五个月内写出了大约一百万行代码、约一千五百个合并请求,团队从三个人起步,后来增到七个,而其中"零行代码"是人手写的。全部由机器产出,人只负责审查和引导。他们自己估算,这大约是人工所需工时的十分之一。每天烧掉的计算量以十亿计,账单是两三千美元一天。
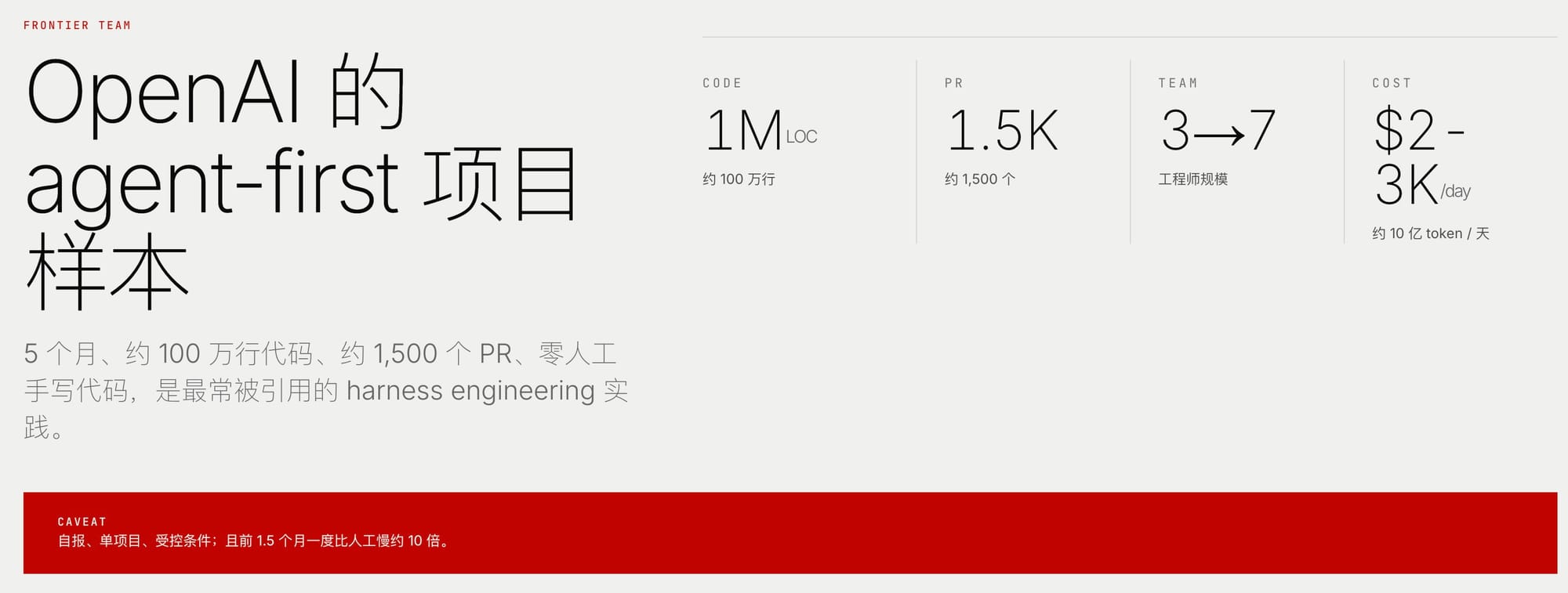
Anthropic 给出的数字更具冲击力。在一份题为《当 AI 开始建造自己》的报告里,他们写道:截至二〇二六年五月,合并进 Anthropic 代码库的代码,超过百分之八十由 Claude 编写——而不久之前,这个比例还只是个位数。报告还称,到二〇二六年第二季度,一个典型工程师每天合并的代码量,是二〇二四年的约八倍。

这些数字读起来令人眩晕。但一个清醒的读者应该在眩晕之前先问几个问题,而最诚实的回答,恰恰来自给出这些数字的人自己。OpenAI 那支团队承认,项目最初的一个半月里,他们比纯人工还慢十倍——机器的优势是在框架搭好之后才显现的。而 Anthropic 在自己的报告里白纸黑字地注明:代码行数是一个有缺陷的度量,"八倍"这个数字几乎肯定夸大了真实的生产力提升。更微妙的是,这份报告发布的背景,是 Anthropic 正在公开呼吁全球放缓前沿 AI 的步伐、且公司临近上市之际——数字从来不只是数字,它们也是叙事的一部分。
如果说实验室的自报数据像是运动员晒出的训练成绩,那么我们也需要一些更中立的裁判。这里有两个。
第一个是 METR 在二〇二五年做的一项随机对照试验——在这个充满主观感受的领域里,它珍贵得近乎孤本。研究者找来十六位资深的开源开发者,让他们在自己熟悉的成熟代码库上完成两百四十六个真实任务,一半允许用当时最前沿的 AI 工具,一半不允许。开始之前,开发者们预测 AI 会让他们快百分之二十四。结束之后,他们感觉 AI 确实让自己快了百分之二十。而真实的测量结果是:**AI 让他们慢了百分之十九。**他们以为自己在加速,其实在减速,而且对此浑然不觉。这个发现里有某种令人不安的东西——它说的不只是工具的局限,更是人对工具的判断力的局限。
第二个裁判是行业内规模最大的体检报告之一:二〇二五年的 DORA 报告,覆盖近五千名从业者、上百小时的定性访谈。它的结论既不唱多也不唱空,而是给出了一个我认为最适合钉在墙上的判断:**AI 是一个放大器。**它确实提升个人的产出和吞吐量,但同时也放大了交付的不稳定性。它能让好团队更好,也能让脆弱的流程更脆弱。而它的价值能不能真正释放,取决于三样东西是否到位:强大的自动化测试、快速的反馈循环、松耦合的架构。
请注意这个结论的妙处。它绕了一大圈,最后落回的恰恰是"框架"和"反馈循环"本身。换句话说,决定成败的不是你用了哪个最聪明的模型,而是你为它搭了一个多好的、能感知后果的世界。循环工程那套发条装置,若是装在一个没有传感器的躯壳上,只会让一台机器更快地撞向同一堵墙。
工程师将变成什么
每一次工具的剧变,都会悄悄重写"工程师"这个词的定义。蒸汽时代如此,编译器出现时如此,如今这一次大概也如此。
如果循环工程描绘的图景成真,工程师的重心会从"写代码"上移——上移到定义意图、设计环境、构建反馈循环、审查与验证。学术界已经在给这件事造词了。研究者 Hassan 等人在一篇关于"agent 化软件工程"的论文里,提出了一个叫"软件工程 3.0"的框架,把未来的工作拆成二元结构:一边是"为人的软件工程",人在其中扮演"agent 教练"的角色;另一边是"为 agent 的软件工程",专门为机器协作者设计制度与工具。他们甚至提出了一个有点官僚气却很实用的概念——"可合并性档案包"(Merge-Readiness Pack):把测试结果、静态分析、性能基准打包在一起,供人类在合并代码前快速做出判断。
这听上去抽象,但落到一个真实的交付团队里,分工其实相当清楚。懂业务的人——产品或业务分析师——负责把用户价值和验收标准说清楚,最好清楚到能直接变成循环的"终止条件"。架构师负责把技术约束和集成模式,编码进那套可复用的框架——他们交付的不再主要是架构文档,而是分层架构加上机械化的强制手段:自定义的检查器、结构测试、持续集成的关卡。一旦代码违反了架构的不变量,红灯立刻亮起,根本到不了人的眼前。而工程师本身,则从"写实现"转向"验证机器的产出是否真的符合规格"。
但这里有一道无论如何不能撤掉的防线,而 Steinberger 这位高产的实践者恰好是它最生动的反面教材。他同时并行五到十个 agent,把合并请求戏称为"提示词请求",信奉"架构高于代码审查"。他最为人称道也最受争议的一点是:他会合并自己根本没读过的代码。这是一种姿态,在他个人的、可以承受失败的项目里或许成立。但 Osmani 的提醒像一句朴素的家训:"你的工作,是交付你确认过能跑的代码。"在高可靠性的领域——比如制造业,比如任何一行代码的失误会蔓延到物理世界的地方——"不读就合并"是一种高风险的赌博。合并前的人工审查,仍然是底线。
没写在宣传册上的陷阱
任何一个新范式在它最兴奋的阶段,都羞于谈论自己的失败模式。但循环工程的失败模式,恰恰是理解它的钥匙。
最直白的陷阱是钱。一个无人值守的循环,是一台持续燃烧令牌的机器。它在你睡觉时也在转,在它空转时也在烧。连 Osmani 本人都坦承,他"仍然持怀疑态度,现在还很早",而成本是他最大的顾虑。
更隐蔽的几个陷阱,则关乎人的心智。有一个词叫"理解债务"(comprehension debt)——循环跑得越快,代码与人对代码的理解之间的鸿沟就越宽。机器在前面飞奔,人在后面追,终有一天追不上,而那一天到来时,没有人真正知道这套系统为什么这样运转。还有一个更刺人的词,叫"认知投降"(cognitive surrender)——人停止思考,开始照单全收,把判断权一点点交出去,直到有一天发现自己已经无力收回。
而即便机器跑得飞快,瓶颈也只是换了个位置。代码生成得越快,人工审查就越成为新的堵点——这是软件版的阿姆达尔定律:你加速了系统的一部分,整体的天花板就压到了你没加速的那部分上。再加上"AI 泔水"(AI slop)这种语法正确、却悄悄违反架构、到处重复逻辑的产物,验证这件事不但没有变轻,反而变重了。机器把"写"变便宜了,却把"读"和"信"变贵了。
这或许是整件事最深的反讽。我们造出了能替我们写代码的循环,但循环宣布的"完成",永远只是一个声明,不是一个证明。验证的责任,那个最终判断"这东西到底行不行"的责任,依然牢牢地落在人的肩上。机器可以写一万行,但有人得为这一万行负责。从这个角度看,循环工程没有把人从回路里解放出来——它只是把人挪到了回路的上方,让人从操作员变成了那个为整台机器的命运签字的人。
清醒的乐观主义者
那么,一位需要在真实世界里做决策的人,该如何对待这个一周大的新词?
我想最诚实的建议是这样的。不要被术语本身迷住。"循环工程"很新,定义未固化,周围环绕着大量带货式的解读;对外谈论时,更稳妥的做法是使用"框架工程""反馈循环""规格驱动开发"这些站得更稳的词,而把"循环工程"作为一个前沿趋势提及。把那些一百万行、百分之八十的实验室数字,当作运动员的训练成绩来读——令人振奋,但来自单一项目、受控条件、且带着商业动机,不能直接搬到一家制造业企业的语境里。把 METR 和 DORA 当作更冷静的参照,记住那个核心判断:AI 是放大器,它放大的是你已有的东西——好的流程被放大成更好的,坏的流程被放大成灾难。
落到行动上,最稳的路径不是冲向无人值守的自动化,而是先把地基夯实。在一两个可验证性高、风险低的模块上试点,先把反馈循环和框架补齐——严格的检查、强类型、集成测试、持续集成的关卡、那份给机器读的项目地图(而且是循序渐进的地图,不是一本千页手册)。引入"制造者(Maker)/检查者(Checker)"的双 agent,但先别开循环的发条。让业务人员用"假如—当—那么"的句式写验收标准,让它们直接成为机器的判据。等这一切跑顺了,再谈规格驱动的四个阶段,每个阶段都留下人工的关卡。只有对那些"终止条件完全可验证、且不触碰生产环境"的任务,才谨慎地放开无人值守的循环。
而衡量收益时,别只盯着代码量。盯着 DORA 那两组指标——吞吐量和稳定性——同时看。如果失败率上升、无人审查就合并的比例上升,就收紧自动化、加强检查者。如果令牌成本超出预算,就放慢节奏。如果机器的首过率始终低于人工,就回头去补传感器——把失败当成"环境缺了某种能力"的信号,而不是"提示词写得不够好"的信号。这是 OpenAI 那套方法论里最深的一句心法:当 agent 失败时,不要去琢磨怎么把话说得更动听,去琢磨它的世界里缺了哪只眼睛、哪只手。
Boris Cherny 说"我的工作是写循环"的那个傍晚,旧金山的天大概还没黑透。他说这句话时带着某种笃定,仿佛在描述一个已经到来的未来。也许他是对的。但历史里塞满了这样的傍晚——有人站起来宣布一个时代的转向,而事后看,转向真的发生了,只是从来没有他们当晚说的那么快、那么干净。循环会转起来,这一点大概不假。真正的问题,永远是谁在循环之上,为它的每一次转动,签下自己的名字。