

作者:Natalya F. Noy 和 Deborah L. McGuinness
斯坦福大学,斯坦福,加州,94305
noy@smi.stanford.edu 和 dlm@ksl.stanford.edu
翻译:GPT4o
英文原版:https://protege.stanford.edu/publications/ontology_development/ontology101.pdf

1 为什么要开发本体?
近年来,本体的开发——即领域术语及其关系的显式正式规范(Gruber 1993)——已经从人工智能实验室的研究领域转移到领域专家的桌面上。本体在万维网上变得越来越普遍。这些网络上的本体从大型分类法(如 Yahoo! 上的网站分类)到产品及其特性分类(如 Amazon.com 上的商品分类)不等。万维网联盟(W3C)正在开发资源描述框架(Resource Description Framework,Brickley 和 Guha 1999),这是一种用于在网页上编码知识的语言,使电子代理能够理解信息。国防高级研究计划局(DARPA)与 W3C 合作,通过扩展 RDF 开发了 DARPA Agent Markup Language (DAML),该语言具有更具表达力的构造,旨在促进网络上的代理交互(Hendler 和 McGuinness 2000)。许多学科现在开发了标准化的本体,领域专家可以使用这些本体来共享和注释其领域中的信息。例如,医学领域已经产生了大型的标准化结构化词汇表,如 SNOMED(Price 和 Spackman 2000)以及统一医学语言系统的语义网络(Humphreys 和 Lindberg 1993)。广泛的通用本体也在逐步出现。例如,联合国开发计划署和 Dun & Bradstreet 联合开发了 UNSPSC 本体,为产品和服务提供术语(www.unspsc.org)。./)
本体为需要在某一领域共享信息的研究人员定义了一个通用的词汇。它包括领域中基本概念及其关系的机器可解释定义。
为什么有人会想要开发本体?原因包括:
- 在人类或软件代理之间共享对信息结构的共同理解
- 促进领域知识的重用
- 明确领域假设
- 将领域知识与操作知识分离
- 分析领域知识
在人类或软件代理之间共享对信息结构的共同理解 是开发本体的一个更常见目标(Musen 1992;Gruber 1993)。例如,假设几个不同的网站包含医学信息或提供医学电子商务服务。如果这些网站共享并发布它们使用的相同基础本体,那么计算机代理就可以从这些不同的网站中提取并汇总信息。这些代理可以使用汇总的信息来回答用户查询或作为其他应用程序的输入数据。
促进领域知识的重用 是最近本体研究激增的一个推动力。例如,许多不同领域的模型需要表示时间的概念。这种表示包括时间间隔、时间点、时间的相对度量等概念。如果一个研究团队详细开发了这样的本体,其他团队就可以直接在其领域中重用。此外,如果我们需要构建一个大型本体,我们可以整合几个现有的本体,这些本体描述了大型领域的部分内容。我们还可以重用一个通用本体,例如 UNSPSC 本体,并扩展它以描述我们感兴趣的领域。
明确实现所依赖的领域假设使得在领域知识发生变化时可以轻松修改这些假设。在编程语言代码中硬编码关于世界的假设不仅使这些假设难以发现和理解,还使得修改变得困难,尤其是对于没有编程专业知识的人。此外,明确的领域知识规范对于新用户来说也很有用,他们需要学习领域中的术语含义。
将领域知识与操作知识分离是本体论的另一个常见用途。我们可以描述一个根据所需规范从组件配置产品的任务,并实现一个独立于产品和组件本身的程序来完成此配置(McGuinness 和 Wright 1998)。然后,我们可以开发一个关于 PC 组件及其特性的本体论,并将算法应用于定制 PC 的配置。同样,我们也可以使用相同的算法来配置电梯,只需将电梯组件本体论“输入”到算法中即可(Rothenfluh 等人 1996)。
分析领域知识在术语的声明性规范可用时变得可能。一旦能够正式分析术语,这对于尝试重用现有本体论以及扩展它们来说都极为有价值(McGuinness 等人 2000)。
通常,领域本体论本身并不是最终目标。开发本体论类似于定义一组数据及其结构,以供其他程序使用。问题解决方法、领域无关的应用程序以及软件代理使用基于本体论构建的知识库作为数据。例如,在本文中,我们开发了一个关于葡萄酒和食物以及葡萄酒与餐点适配的本体论。该本体论可以作为餐厅管理工具套件中某些应用程序的基础:一个应用程序可以为当天菜单创建葡萄酒建议,或者回答服务员和顾客的查询。另一个应用程序可以分析酒窖的库存清单,并建议扩展哪些葡萄酒类别以及为即将推出的菜单或食谱购买哪些特定葡萄酒。
关于本指南
我们基于使用 Protégé-2000(Protege 2000)、Ontolingua(Ontolingua 1997)和 Chimaera(Chimaera 2000)作为本体编辑环境的经验编写了本指南。在本指南中,我们使用 Protégé-2000 作为示例工具。
贯穿本指南的葡萄酒和食物示例松散地基于一篇描述 CLASSIC 的论文中提出的示例知识库。CLASSIC 是一种基于描述逻辑方法的知识表示系统(Brachman 等,1991)。CLASSIC 教程(McGuinness 等,1994)进一步发展了这一示例。Protégé-2000 和其他基于框架的系统以声明方式描述本体,明确指出类层次结构以及个体属于哪些类。
本指南中的一些本体设计理念源自面向对象设计的相关文献(Rumbaugh 等,1991;Booch 等,1997)。然而,本体开发与面向对象编程中的类和关系设计有所不同。面向对象编程主要围绕类的方法展开——程序员根据类的操作性属性做出设计决策,而本体设计者则根据类的结构性属性做出决策。因此,本体中的类结构及类之间的关系与面向对象程序中类似领域的结构有所不同。
本指南无法涵盖本体开发者可能需要处理的所有问题,我们也无意解决所有问题。相反,我们试图提供一个起点;一个初步的指南,帮助新手本体设计者开发本体。在最后,我们建议一些资源以便在领域需要时查阅更复杂的结构和设计机制的解释。
最后,没有单一正确的本体设计方法,我们也没有尝试定义一种方法。本指南中提出的理念是我们在自己的本体开发经验中发现有用的内容。在本指南的结尾,我们提供了一份参考文献列表,供读者了解其他方法论。
2 本体包含什么内容?
人工智能文献中对本体的定义有很多,其中许多定义相互矛盾。为了本指南的目的,本体是对某一领域中概念的正式明确描述(类 classes(有时称为概念 concepts))、描述每个概念各种特征和属性的属性(槽 slots (有时称为角色 roles 或属性 properties)),以及对槽的限制(面 facets(有时称为角色限制 role restrictions))。本体与一组类的个体实例 instances一起构成了一个知识库 knowledge base。实际上,本体与知识库之间界限非常模糊。
类是大多数本体的核心。类描述领域中的概念。例如,葡萄酒类代表所有葡萄酒。具体的葡萄酒是该类的实例。您在阅读本文档时杯中所盛的波尔多葡萄酒是波尔多葡萄酒类的一个实例。一个类可以有子类,子类表示比超类更具体的概念。例如,我们可以将所有葡萄酒类分为红葡萄酒、白葡萄酒和桃红葡萄酒。或者,我们可以将所有葡萄酒类分为起泡酒和非起泡酒。
槽描述类和实例的属性:Château Lafite Rothschild Pauillac 葡萄酒酒体饱满;它由 Château Lafite Rothschild 酒庄生产。在这个例子中,我们有两个描述葡萄酒的槽:酒体槽,其值为饱满;生产者槽,其值为 Château Lafite Rothschild 酒庄。在类级别,我们可以说葡萄酒类的实例将具有描述其风味、酒体、糖分水平、生产者等的槽。
所有类 Wine 及其子类 Pauillac 的实例都具有一个名为 maker 的槽,其值是类 Winery 的一个实例(如图 1 所示)。类 Winery 的所有实例都具有一个名为 produces 的槽,该槽指向该酒厂生产的所有酒(类 Wine 及其子类的实例)。
在实际操作中,开发本体包括:
- 定义本体中的类,
- 将类安排在分类(子类–超类)层次结构中,
- 定义槽并描述这些槽的允许值,
- 为实例填充槽的值。
然后,我们可以通过定义这些类的单个实例,填充具体的槽值信息以及额外的槽限制来创建一个知识库。
我们将类名首字母大写,并以小写字母开头命名槽名。我们还使用打字机字体表示示例本体中的所有术语。
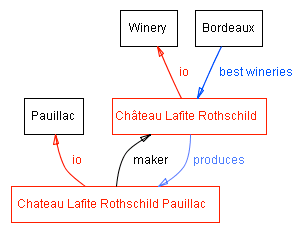
图 1. 酒类领域中的一些类、实例及其关系。我们使用黑色表示类,红色表示实例。直接链接表示槽,内部链接如 instance-of 和 subclass-of。
3 一个简单的知识工程方法论
如前所述,开发本体没有唯一“正确”的方法或方法论。在此,我们讨论需要考虑的一些一般问题,并提供一种可能的本体开发过程。我们描述了一种迭代的本体开发方法:从粗略的初步本体开始,然后对不断发展的本体进行修订和完善,并填充细节。在此过程中,我们讨论设计者需要做出的建模决策,以及不同解决方案的优缺点和影响。
首先,我们想强调一些本体设计中的基本规则,这些规则我们会多次提及。这些规则可能显得相当教条,但在许多情况下,它们有助于做出设计决策。
- 没有唯一正确的方式来建模一个领域——总是有可行的替代方案。最佳解决方案几乎总是取决于您所考虑的应用程序以及您预期的扩展。
- 本体开发必然是一个迭代过程。
- 本体中的概念应接近于您感兴趣领域中的对象(物理或逻辑)和关系。这些概念很可能是描述您领域的句子中的名词(对象)或动词(关系)。
也就是说,决定我们将如何使用本体,以及本体的详细程度或通用程度,将指导许多后续的建模决策。在多个可行的替代方案中,我们需要确定哪一个更适合预期任务、更直观、更可扩展且更易维护。我们还需要记住,本体是现实世界的模型,本体中的概念必须反映这一现实。在定义本体的初始版本后,我们可以通过在应用程序或问题解决方法中使用它,或与领域专家讨论它,或者两者兼而有之,来评估和调试它。结果是,我们几乎肯定需要修订初始本体。这种迭代设计过程可能会贯穿整个本体生命周期。
步骤 1. 确定本体的领域和范围
我们建议通过定义本体的领域和范围来开始本体开发。也就是说,回答几个基本问题:
- 本体将涵盖的领域是什么?
- 我们将如何使用本体?
- 本体中的信息应该回答哪些类型的问题?
- 谁将使用和维护本体?
这些问题的答案可能会在本体设计过程中发生变化,但在任何给定时间,它们都有助于限制模型的范围。
考虑我们之前介绍的关于葡萄酒和食物的本体论。本体论的领域是对食物和葡萄酒的表示。我们计划使用这个本体论来开发建议葡萄酒与食物良好搭配的应用程序。
自然地,描述不同类型葡萄酒、主要食物类型、葡萄酒与食物良好搭配的概念以及不良搭配的概念将会出现在我们的本体论中。同时,尽管管理酒厂库存或餐厅员工的概念与葡萄酒和食物的概念有一定关联,但这些概念不太可能被纳入本体论。
如果我们设计的本体论将用于帮助自然语言处理葡萄酒杂志中的文章,那么可能需要在本体论中包含概念的同义词和词性信息。如果本体论将用于帮助餐厅顾客决定点哪种葡萄酒,我们需要包括零售价格信息。如果本体论用于帮助葡萄酒买家储备酒窖,则可能需要包括批发价格和供应情况。如果维护本体论的人使用的语言与本体论用户使用的语言不同,我们可能需要提供语言之间的映射。
能力问题
确定本体范围的一种方法是列出基于本体的知识库应该能够回答的问题清单,即能力问题(Gruninger 和 Fox 1995)。这些问题将作为后续的试金石:本体是否包含足够的信息来回答这些类型的问题?答案是否需要特定领域的详细信息或特定区域的表示?这些能力问题只是一个草图,不需要详尽无遗。
在葡萄酒和美食领域,以下是可能的能力问题:
- 选择葡萄酒时应该考虑哪些葡萄酒特性?
- 波尔多是红葡萄酒还是白葡萄酒?
- 赤霞珠是否适合搭配海鲜?
- 烤肉的最佳葡萄酒选择是什么?
- 哪些葡萄酒特性会影响其与某道菜的适配性?
- 某种葡萄酒的香气或酒体是否会随年份变化?
- 哪些年份是纳帕仙粉黛的好年份?
从这些问题来看,本体将包括关于各种葡萄酒特性和类型的信息、年份(好年份和坏年份)、与选择适当葡萄酒相关的食品分类,以及葡萄酒与美食的推荐搭配。
步骤 2. 考虑重用现有本体
几乎总是值得考虑别人已经完成的工作,并检查我们是否可以为特定领域和任务优化和扩展现有资源。如果我们的系统需要与已经采用特定本体或受控词汇表的其他应用程序交互,重用现有本体可能是必要的。许多本体已经以电子形式提供,可以导入到您使用的本体开发环境中。本体表达的形式通常并不重要,因为许多知识表示系统可以导入和导出本体。即使知识表示系统无法直接处理特定形式,本体从一种形式转换到另一种形式的任务通常并不困难。
网络和文献中有可重用本体的库。例如,我们可以使用 Ontolingua 本体库(http://www.ksl.stanford.edu/software/ontolingua/)或 DAML 本体库(http://www.daml.org/ontologies/)。此外,还有许多公开的商业本体(例如 UNSPSC (www.unspsc.org)、RosettaNetrosettanet-852m/) (www.rosettanet.org)、DMOZdmoz-im3g/) (www.dmoz.org))。)./)
例如,可能已经存在一个关于法国葡萄酒的知识库。如果我们能够导入这个知识库及其所基于的本体,我们不仅可以获得法国葡萄酒的分类,还可以初步获得用于区分和描述葡萄酒的特性分类。葡萄酒属性的列表可能已经可以从商业网站(如 www.wines.com)获得,这些网站的客户会用来购买葡萄酒。,-rz1h4j48a583fmjikihxwqsg6bd8djpu70q2tr7ibq0c204gezlm1h./)
然而,在本指南中,我们将假设不存在相关的本体,并从头开始开发本体。
步骤 3. 枚举本体中的重要术语
列出我们希望能够陈述或向用户解释的所有术语是很有用的。我们希望讨论哪些术语?这些术语有哪些属性?我们希望对这些术语说些什么?例如,与葡萄酒相关的重要术语包括:葡萄酒、葡萄、酒庄、产地、葡萄酒的颜色、酒体、风味和糖分含量;不同类型的食物,如鱼和红肉;葡萄酒的子类型,如白葡萄酒等。最初,重要的是要获得一个全面的术语列表,而不必担心它们所代表的概念之间的重叠、术语之间的关系、概念可能具有的任何属性,或者这些概念是类还是槽。
接下来的两个步骤——开发类层次结构和定义概念属性(槽)——紧密相连。很难先完成其中一个步骤然后再进行另一个。通常,我们会先在层次结构中创建一些概念的定义,然后继续描述这些概念的属性,依此类推。这两个步骤也是本体设计过程中最重要的步骤。我们将在这里简要描述它们,并在接下来的两个部分中讨论需要考虑的更复杂问题、常见的陷阱、需要做出的决策等。
步骤 4. 定义类及类层次结构
在开发类层次结构时,有几种可能的方法(Uschold 和 Gruninger 1996):
- 自顶向下的开发过程从定义领域中最一般的概念开始,然后逐步对这些概念进行细化。例如,我们可以从为“葡萄酒”和“食物”这两个一般概念创建类开始。然后通过创建一些子类来细化“葡萄酒”类:白葡萄酒、红葡萄酒、桃红葡萄酒。我们可以进一步细分“红葡萄酒”类,例如,将其分类为西拉(Syrah)、红勃艮第(Red Burgundy)、赤霞珠(Cabernet Sauvignon)等。
- 自底向上的开发过程从定义最具体的类(层次结构的叶子)开始,然后将这些类分组为更一般的概念。例如,我们可以从定义“波雅克”(Pauillac)和“玛歌”(Margaux)葡萄酒的类开始。然后为这两个类创建一个共同的超类——“梅多克”(Medoc),而“梅多克”又是“波尔多”(Bordeaux)的一个子类。
- 组合开发过程结合了自顶向下和自底向上的方法:我们首先定义一些更显著的概念,然后适当地对它们进行泛化和细化。我们可能从几个顶层概念(如“葡萄酒”)和几个具体概念(如“玛歌”)开始。然后将它们与一个中层概念(如“梅多克”)关联起来。接着,我们可能希望生成所有来自法国的地区性葡萄酒类,从而生成许多中层概念。
图 2 显示了不同层次的通用性之间的可能划分。
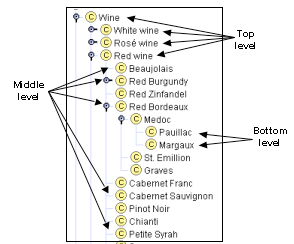
图 2. 葡萄酒分类法的不同层次:**“葡萄酒”是最一般的概念。“红葡萄酒”、“白葡萄酒”和“桃红葡萄酒”是一般的顶层概念。“波雅克”和“玛歌”是层次结构中最具体的类(或底层概念)。
这三种方法本身没有哪一种比其他方法更好。选择哪种方法在很大程度上取决于开发者对领域的个人看法。如果开发者对领域有系统的自顶向下的视角,那么使用自顶向下的方法可能会更容易。组合方法对于许多本体开发者来说通常是最简单的,因为“中间层”的概念往往是领域中更具描述性的概念(Rosch 1978)。
如果你倾向于通过区分最一般的分类来思考葡萄酒,那么自顶向下的方法可能更适合你。如果你更愿意从具体示例入手,那么自底向上的方法可能更合适。
无论选择哪种方法,我们通常从定义类开始。从步骤 3 中创建的列表中,我们选择描述具有独立存在的对象的术语,而不是描述这些对象的术语。这些术语将成为本体中的类,并成为类层次结构中的锚点。我们通过询问一个对象是否通过成为某个类的实例,必然(即根据定义)也是另一个类的实例,将类组织成一个层次化的分类法。
如果类 A 是类 B 的超类,那么 B 的每个实例也都是 A 的实例。
换句话说,类 B 表示一个“属于”类 A 的概念。
例如,每一种黑皮诺葡萄酒必然是一种红葡萄酒。因此,黑皮诺类是红葡萄酒类的子类。
图 2 显示了葡萄酒本体的类层次结构的一部分。第 4 节详细讨论了定义类层次结构时需要注意的事项。
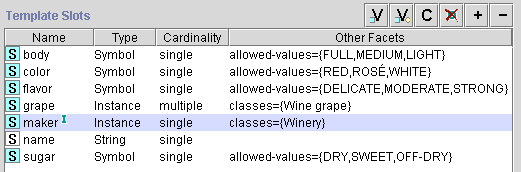
图 3. 类 Wine 的槽及这些槽的面。 maker 槽旁的“I”图标表示该槽具有逆关系(第 5.1 节)
步骤 5. 定义类的属性——槽
仅仅定义类不足以回答步骤 1 中的能力问题。一旦我们定义了一些类,就必须描述概念的内部结构。
我们已经从步骤 3 中创建的术语列表中选择了类。剩余的大多数术语可能是这些类的属性。这些术语包括例如葡萄酒的颜色、酒体、风味、含糖量以及酒厂的位置。
对于列表中的每个属性,我们必须确定它描述的是哪个类。这些属性将成为附加到类上的槽。因此,Wine 类将具有以下槽:颜色(color)、酒体(body)、风味(flavor)和含糖量(sugar)。而 Winery 类将具有一个位置(location)槽。
通常,有几种类型的对象属性可以成为本体中的槽:
- “内在 intrinsic”属性,例如葡萄酒的风味;
- “外在 extrinsic”属性,例如葡萄酒的名称和产地;
- 部分 parts 属性,如果对象是结构化的;这些可以是物理的或抽象的“部分”(例如,一顿饭的各道菜);
- 与其他个体的关系 relationships to other individuals ;这些是类的个体成员与其他项之间的关系(例如,葡萄酒的制造者,表示葡萄酒与酒厂之间的关系,以及葡萄酒所用的葡萄)。
因此,除了我们之前识别的属性外,我们还需要为 Wine 类添加以下槽:名称(name)、产地(area)、制造者(maker)、葡萄(grape)。图 3 显示了 Wine 类的槽。
类的所有子类继承该类的槽。例如,Wine 类的所有槽将被 Wine 的所有子类继承,包括 Red Wine 和 White Wine。我们将为 Red Wine 类添加一个额外的槽:单宁水平(低、中或高)。单宁水平槽将被所有表示红葡萄酒的类(如 Bordeaux 和 Beaujolais)继承。
槽应附加到最通用的可以具有该属性的类。例如,葡萄酒的酒体和颜色应附加到 Wine 类,因为它是实例具有酒体和颜色的最通用类。
步骤 6. 定义槽的面 facets
槽可以具有不同的面 facets,用于描述值类型、允许值、值的数量(基数)以及槽值可以具有的其他特性。例如,名称槽的值(如“葡萄酒的名称”)是一个字符串。也就是说,名称是一个值类型为字符串的槽。生产槽(如“酒厂生产这些葡萄酒”)可以具有多个值,这些值是 Wine 类的实例。也就是说,生产是一个值类型为实例的槽,允许的类是 Wine。
我们现在将描述几种常见的面。
槽的基数 Slot cardinality
槽的基数定义了一个槽可以拥有多少个值。一些系统仅区分单一基数(最多允许一个值)和多重基数(允许任意数量的值)。例如,葡萄酒的酒体将是一个单一基数槽(每种葡萄酒只能有一个酒体)。由某个酒厂生产的葡萄酒则填充了一个多重基数槽,该槽属于酒厂类。
某些系统允许通过指定最小和最大基数来更精确地描述槽值的数量。最小基数为 N 表示一个槽必须至少有 N 个值。例如,葡萄酒的葡萄槽的最小基数为 1:每种葡萄酒至少由一种葡萄品种酿造。最大基数为 M 表示一个槽最多可以有 M 个值。单一品种葡萄酒的葡萄槽的最大基数为 1:这些葡萄酒仅由一种葡萄品种酿造。有时将最大基数设置为 0 可能是有用的,这表明该槽在特定子类中不能有任何值。
槽值类型 Slot-value type
值类型特性描述了哪些类型的值可以填充槽。以下是一些常见的值类型:
- 字符串 是最简单的值类型,用于诸如名称的槽:值是一个简单的字符串。
- 数字(有时使用更具体的值类型,如浮点数和整数)描述具有数值的槽。例如,葡萄酒的价格可以是浮点数值类型。
- 布尔值 槽是简单的是–否标志。例如,如果我们选择不将起泡酒表示为一个单独的类,那么葡萄酒是否为起泡酒可以表示为布尔值槽的值:如果值为“true”(“是”),则葡萄酒是起泡酒;如果值为“false”(“否”),则葡萄酒不是起泡酒。
- 枚举 槽为槽指定一组特定的允许值。例如,我们可以指定风味槽可以取以下三种可能值之一:强烈、中等和细腻。在 Protégé-2000 中,枚举槽的类型为 Symbol。
- 实例 类型槽允许定义个体之间的关系。具有实例值类型的槽还必须定义允许的类列表,这些实例可以来自这些类。例如,酒厂类的槽“生产”可以具有葡萄酒类的实例作为其值。
图 4 显示了酒厂类中“生产”槽的定义。
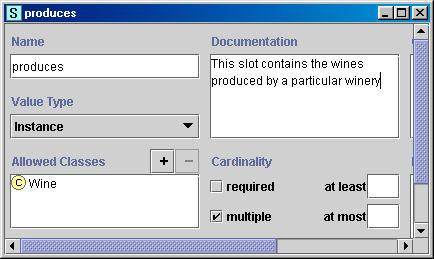
图 4. 定义了酒厂生产的葡萄酒的槽“生产”。该槽具有多重基数、实例值类型,并且允许的值类为葡萄酒类。
槽的域和范围 Domain and range of a slot
实例类型槽的允许类通常被称为槽的范围。在图 4 的示例中,葡萄酒类是“生产”槽的范围。一些系统允许在槽附加到特定类时限制槽的范围。
槽附加到的类或槽描述的类被称为槽的域。酒厂类是“生产”槽的域。在将槽附加到类的系统中,槽附加到的类通常构成该槽的域,无需单独指定域。
确定槽的域和范围的基本规则类似:
在为槽定义域或范围时,找到可以分别作为槽域或范围的最通用的类或类。另一方面,不要定义过于通用的域和范围:槽域中的所有类都应该由该槽描述,槽范围中的所有类的实例都应该是该槽的潜在填充值。不要选择过于通用的类作为范围(例如,一个人可能不希望将范围设为 THING),但会希望选择一个可以涵盖所有填充项的类
与其列出 Wine 类的所有可能子类作为 produces 的范围,
3 有些系统仅通过一个类来指定值类型,而不需要特别声明实例类型槽。
槽,只需列出 Wine。同时,我们不希望将槽的范围指定为 THING——本体中最通用的类。
更具体地说:如果定义槽的范围或领域的类列表中包含一个类及其子类,则移除子类。
如果槽的范围同时包含 Wine 类和 Red Wine 类,我们可以从范围中移除 Red Wine,因为它并未添加任何新信息:Red Wine 是 Wine 的子类,因此槽范围已经隐含地包括了它以及 Wine 类的所有其他子类。
如果定义槽的范围或领域的类列表包含一个类 A 的所有子类,但不包含类 A 本身,则范围应仅包含类 A,而不是子类。
与其将槽的范围定义为包含 Red Wine、White Wine 和 Rose Wine(列举 Wine 的所有直接子类),我们可以将范围限制为 Wine 类本身。
如果定义槽的范围或领域的类列表包含类 A 的所有子类,但缺少几个子类,请考虑类 A 是否会成为更合适的范围定义。
在将槽附加到类的系统中,这与将类添加到槽的领域是相同的,适用相同的规则:一方面,我们应尽量使其尽可能通用;另一方面,我们必须确保每个附加槽的类确实可以拥有槽所代表的属性。我们可以将 tannin level 槽附加到表示红酒的每个类(例如 Bordeaux、Merlot、Beaujolais 等)。然而,由于所有红酒都有 tannin level 属性,我们应该将槽附加到更通用的 Red Wines 类。进一步泛化 tannin level 槽的领域(通过将其附加到 Wine 类)则不正确,因为我们不会用 tannin level 来描述白酒,例如。
步骤 7. 创建实例
最后一步是创建层级结构中各类的具体实例。定义一个类的具体实例需要以下步骤:
(1) 选择一个类,(2) 创建该类的具体实例,以及 (3) 填充槽值。例如,我们可以创建一个名为 Chateau-Morgon-Beaujolais 的具体实例来表示一种特定类型的 Beaujolais 葡萄酒。Chateau-Morgon-Beaujolais 是 Beaujolais 类的一个实例,代表所有 Beaujolais 葡萄酒。该实例定义了以下槽值(图 5):
- 酒体:轻盈
- 颜色:红色
- 风味:细腻
- 单宁水平:低
- 葡萄:Gamay(Wine grape 类的一个实例)
- 酿造者:Chateau-Morgon(Winery 类的一个实例)
- 产区:Beaujolais(Wine-Region 类的一个实例)
- 糖分:干型
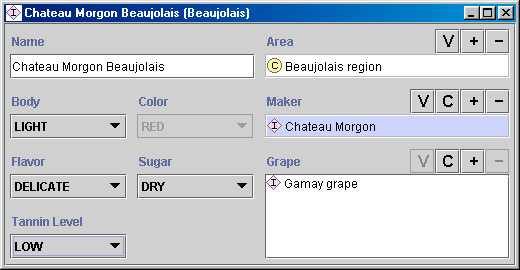
图 5. Beaujolais 类的一个实例定义。该实例是来自 Beaujolais 产区的 Chateau Morgon Beaujolais,由 Chateau Morgon 酒庄使用 Gamay 葡萄酿造而成。它具有轻盈的酒体、细腻的风味、红色的颜色和低单宁水平,是一种干型葡萄酒。
4 定义类及类层级结构
本节讨论在定义类及类层级结构(第 3 节中的步骤 4)时需要注意的事项以及容易犯的错误。如前所述,对于任何给定领域,没有单一正确的类层级结构。层级结构取决于本体的可能用途、应用所需的细节级别、个人偏好,有时还取决于与其他模型的兼容性要求。然而,我们将讨论在开发类层级结构时需要牢记的几个指导原则。在定义了大量新类之后,退一步检查生成的层级结构是否符合这些指导原则是很有帮助的。
4.1 确保类层级结构的正确性
“是一个”关系
类层级结构表示一种“是一个”关系:如果 A 类是 B 类的子类,则 A 的每个实例也是 B 的一个实例。例如,Chardonnay 是 White wine 的一个子类。另一种理解分类关系的方法是“某种类型”的关系:Chardonnay 是 White wine 的一种类型。喷气式客机是飞机的一种类型。肉类是食物的一种类型。
一个类的子类表示的是一种“某种类型”的概念,
而这个概念是其父类所代表的概念的一部分。
单一葡萄酒不是所有葡萄酒的子类
一个常见的建模错误是在层级结构中同时包含同一概念的单数和复数版本,并将前者定义为后者的子类。例如,定义一个 Wines 类和一个 Wine 类,并将 Wine 定义为 Wines 的子类是错误的。一旦将层级结构理解为表示“某种类型”的关系,这种建模错误就会变得显而易见:单一的 Wine 并不是 某种类型的 Wines。避免此类错误的最佳方法是始终在命名类时使用单数或复数形式(有关命名概念的讨论,请参见第 6 节)。
层级关系的传递性
子类关系是传递的:
如果 B 是 A 的子类,且 C 是 B 的子类,那么 C 也是 A 的子类。
例如,我们可以定义一个类 Wine,然后定义一个类 White wine 作为 Wine 的子类。接着,我们定义一个类 Chardonnay 作为 White wine 的子类。子类关系的传递性意味着类 Chardonnay 也是 Wine 的子类。有时我们会区分直接子类和间接子类。直接子类是某个类的“最近”子类:在层级结构中,类与其直接子类之间没有其他类。也就是说,在层级结构中,类与其直接超类之间没有其他类。在我们的例子中,Chardonnay 是 White wine 的直接子类,而不是 Wine 的直接子类。
类层次结构的演变
随着领域的演变,保持一致的类层次结构可能会变得具有挑战性。例如,多年来,所有的 Zinfandel 葡萄酒都是红葡萄酒。因此,我们将 Zinfandel 葡萄酒类定义为红葡萄酒类的子类。然而,有时酿酒师开始压榨葡萄,并立即去除葡萄中产生颜色的部分,从而改变了最终葡萄酒的颜色。于是,我们得到了颜色为玫瑰色的“白 Zinfandel”。现在,我们需要将 Zinfandel 类拆分为两个 Zinfandel 类——白 Zinfandel 和红 Zinfandel,并分别将它们分类为玫瑰葡萄酒和红葡萄酒的子类。
类及其名称
区分类与其名称是非常重要的:
类代表领域中的概念,而不是表示这些概念的词语。
类的名称可能会因术语的选择而改变,但术语本身代表的是世界中的客观现实。例如,我们可以创建一个名为 Shrimps 的类,然后将其重命名为 Prawns——该类仍然表示相同的概念。与虾类菜肴相关的适配葡萄酒组合应该同样适用于对虾菜肴。从更实际的角度来看,以下规则应始终遵循:
同一概念的同义词不代表不同的类。
同义词只是一个概念或术语的不同名称。因此,我们不应该创建一个名为 Shrimp 的类、一个名为 Prawn 的类,以及可能还有一个名为 Crevette 的类。相反,应该只有一个类,名称可以是 Shrimp 或 Prawn。许多系统允许为类关联一组同义词、翻译或显示名称。如果系统不允许这些关联,同义词可以始终列在类的文档中。
避免类循环
我们应当避免在类层次结构中出现循环。当某个类 A 有一个子类 B,同时 B 又是 A 的超类时,我们称该层次结构中存在循环。在层次结构中创建这样的循环等同于声明类 A 和类 B 是等价的:所有 A 的实例都是 B 的实例,所有 B 的实例也都是 A 的实例。实际上,由于 B 是 A 的子类,所有 B 的实例必须是类 A 的实例。而由于 A 是 B 的子类,所有 A 的实例也必须是类 B 的实例。
4.2 分析类层次结构中的兄弟类
类层次结构中的兄弟类
兄弟类是指层次结构中同属于同一个父类的直接子类(参见第 4.1 节)。
层次结构中的所有兄弟类(除根节点的兄弟类外)必须处于相同的概括层级。
例如,白葡萄酒(White wine)和霞多丽(Chardonnay)不应是同一个类(例如,Wine)的子类。白葡萄酒是一个比霞多丽更为概括的概念。兄弟类应表示“沿着同一条线”的概念,就像书中同级的章节处于相同的概括层级一样。从这个意义上说,类层次结构的要求与书的纲要要求类似。
然而,层次结构根节点的概念(通常表示为某个非常通用的类的直接子类,例如 Thing)代表领域的主要划分,不必是相似的概念。
多少是太多,多少是太少?
对于一个类应该有多少直接子类,没有硬性规定。然而,许多结构良好的本体通常有两到十二个直接子类。因此,我们有以下两条指导原则:
如果一个类只有一个直接子类,可能存在建模问题或本体尚未完成。
如果一个类有超过十二个子类,则可能需要添加额外的中间类别。
第一条规则类似于排版规则,即项目符号列表不应只有一个项目符号。例如,大多数红色勃艮第葡萄酒是金丘(Côtes d’Or)葡萄酒。假设我们只想表示这种主要类型的勃艮第葡萄酒。我们可以创建一个类 Red Burgundy,然后创建一个单一子类 Cotes d’Or(图 6a)。然而,如果在我们的表示中,红色勃艮第葡萄酒和金丘葡萄酒本质上是等价的(所有红色勃艮第葡萄酒都是金丘葡萄酒,所有金丘葡萄酒都是红色勃艮第葡萄酒),那么创建 Cotes d’Or 类是没有必要的,并且不会为表示添加任何新信息。如果我们要包括夏隆内丘(Côtes Chalonnaise)葡萄酒,这是一种来自金丘以南地区的较便宜的勃艮第葡萄酒,那么我们将为 Burgundy 类创建两个子类:Cotes d’Or 和 Cotes Chalonnaise(图 6b)


图 6. 红色勃艮第类的子类。只有一个子类通常表明建模存在问题。
假设现在我们将所有类型的葡萄酒列为 Wine 类的直接子类。这份列表将包括更为概括的葡萄酒类型,例如 Beaujolais 和 Bordeaux,以及更为具体的类型,例如 Paulliac 和 Margaux(图 6a)。Wine 类有太多直接子类,实际上,为了使本体更有组织地反映不同类型的葡萄酒,Medoc 应该是 Bordeaux 的子类,Cotes d’Or 应该是 Burgundy 的子类。此外,添加像 Red wine 和 White wine 这样的中间类别也能反映许多人对葡萄酒领域的概念模型(图 6b)。
然而,如果在长长的兄弟类列表中没有自然类别来对概念进行分组,则无需创建人工类别——只需保持原样即可。毕竟,本体是现实世界的反映,如果现实世界中不存在分类,那么本体也应该反映这一点。
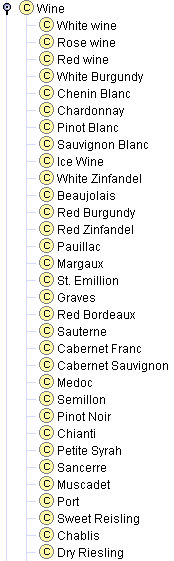
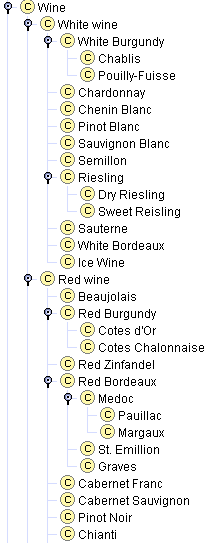
图 7. 葡萄酒分类。将所有葡萄酒和类型列为一类与创建多个分类层级。
4.3 多重继承
大多数知识表示系统允许类层次结构中的多重继承:一个类可以是多个类的子类。假设我们希望创建一个单独的甜酒类——甜酒类。波特酒既是红酒又是甜酒。因此,我们定义一个波特酒类,使其有两个父类:红酒类和甜酒类。波特酒类的所有实例将同时是红酒类和甜酒类的实例。波特酒类将从其两个父类继承插槽及其属性。因此,它将从甜酒类继承糖插槽的值 SWEET,并从红酒类继承单宁水平插槽和颜色插槽的值。
4.4 何时引入新类(或不引入)
在建模过程中,最难做出的决定之一是何时引入新类,或何时通过不同的属性值来表示区分。处理一个极度嵌套的层次结构(包含许多多余的类)和一个非常扁平的层次结构(类太少,信息过多地编码在插槽中)都很困难。然而,找到适当的平衡并不容易。
以下是一些帮助决定何时在层次结构中引入新类的经验法则。
一个类的子类通常 (1) 具有超类没有的附加属性,或 (2) 具有与超类不同的约束,或 (3) 参与与超类不同的关系
红酒可以具有不同的单宁水平,而这一属性并不用于描述一般的酒类。甜酒的糖插槽值为 SWEET,而甜酒类的超类并非如此。黑皮诺红酒可能适合搭配海鲜,而其他红酒则不适合。换句话说,我们通常只有在能够对这个类说出超类无法表达的内容时,才在层次结构中引入新类。
从实际角度来看,每个子类应该要么添加新的插槽,要么定义新的插槽值,要么覆盖继承插槽的一些属性。
然而,有时即使新类没有引入任何新属性,创建新类也可能是有用的。
术语层次结构中的类不一定需要引入新属性
例如,一些本体包括领域中常用术语的大型参考层次结构。例如,一个电子病历系统的底层本体可能包括各种疾病的分类。这种分类可能仅仅是一个术语层次结构,而没有属性(或具有相同的一组属性)。在这种情况下,将术语组织成层次结构而不是平面列表仍然是有用的,因为它将 (1) 使探索和导航更容易,(2) 使医生能够轻松选择适合情况的术语的通用性级别。
另一个在没有任何新属性的情况下引入新类的原因是为了建模领域专家通常区分的概念,即使我们可能决定不对这种区分本身进行建模。由于我们使用本体来促进领域专家之间以及领域专家与知识系统之间的交流,我们希望在本体中反映专家对领域的看法。
最后,我们不应该为每个额外的约束创建一个类的子类。例如,我们引入了红酒类、白酒类和桃红酒类,因为这种区分在酒类领域是自然的。我们没有为精致酒、适中酒等引入类。在定义类层次结构时,我们的目标是平衡创建有助于类组织的新类与创建过多类之间的关系。
4.5 新的类还是属性值?
在建模一个领域时,我们经常需要决定是否将某种特定的区分(例如白葡萄酒、红葡萄酒或桃红葡萄酒)建模为属性值,还是作为一组类。这通常取决于领域的范围以及当前任务的需求。
我们是创建一个“白葡萄酒”类,还是简单地创建一个“葡萄酒”类并为其“颜色”槽填充不同的值?答案通常取决于我们为本体定义的范围。在我们的领域中,“白葡萄酒”这一概念有多重要?如果葡萄酒在领域中仅占据边缘地位,并且葡萄酒是否是白色对其与其他对象的关系没有特别的影响,那么我们不应该为白葡萄酒引入一个单独的类。例如,在一个生产葡萄酒标签的工厂使用的领域模型中,任何颜色的葡萄酒标签规则都是相同的,这种区分并不重要。另一方面,在表示葡萄酒、食物及其适当搭配的模型中,红葡萄酒与白葡萄酒非常不同:它们与不同的食物搭配,具有不同的属性,等等。同样,葡萄酒的颜色对于我们可能用来确定品酒顺序的葡萄酒知识库来说是重要的。因此,我们为“白葡萄酒”创建一个单独的类。
如果具有不同槽值的概念成为其他类中不同槽的约束条件,那么我们应该为这种区分创建一个新的类。
否则,我们在槽值中表示这种区分。
类似地,我们的葡萄酒本体中有“红梅洛”和“白梅洛”这样的类,而不是一个包含所有梅洛葡萄酒的单一类:红梅洛和白梅洛实际上是不同的葡萄酒(由同一种葡萄酿造),如果我们正在开发一个详细的葡萄酒本体,这种区分是重要的。
如果某种区分在领域中很重要,并且我们认为具有不同区分值的对象是不同种类的对象,那么我们应该为这种区分创建一个新的类。
考虑类的潜在个体实例也可能有助于决定是否引入一个新的类。
一个个体实例所属的类不应该经常改变。
通常,当我们使用概念的外在属性而非内在属性来区分类时,这些类的实例将不得不频繁地从一个类迁移到另一个类。例如,“冷藏葡萄酒”不应该是描述餐厅中葡萄酒瓶的本体中的一个类。“冷藏”属性应该只是瓶中葡萄酒的一个属性,因为“冷藏葡萄酒”的实例可以很容易地不再是该类的实例,然后又重新成为该类的实例。
通常,数字、颜色、位置是槽值,并不会导致新类的创建。然而,葡萄酒是一个显著的例外,因为葡萄酒的颜色在描述葡萄酒时是至关重要的。
另一个例子是人体解剖学本体。当我们表示肋骨时,我们是否为“第一左肋骨”、“第二左肋骨”等创建一个类?还是创建一个“肋骨”类,并为其设置顺序和侧位(左-右)槽?如果我们在本体中表示的每根肋骨的信息差异显著,那么我们确实应该这样做。
在这里我们假设每个解剖器官是一个类,因为我们还希望能够谈论“约翰的第一左肋骨”。现有人的个体器官将在我们的本体中表示为个体实例。
创建一个针对每根肋骨的类。也就是说,如果我们希望表示每根肋骨的邻接关系和位置信息(这些信息因肋骨而异),以及每根肋骨的特定功能和保护的器官,我们需要创建这些类。如果我们在稍低的通用性层次上建模解剖学,并且所有肋骨在我们的潜在应用中都非常相似(例如,我们只讨论 X 光片上哪根肋骨骨折,而不涉及身体其他部分的影响),我们可能希望简化层次结构,仅创建一个 Rib 类,并包含两个槽:侧位和顺序。
4.6 是实例还是类?
决定某个特定概念在本体中是一个类还是一个个体实例,取决于本体的潜在应用。确定类的边界和个体实例的起点,首先需要决定表示的最低粒度级别。而粒度级别又由本体的潜在应用决定。换句话说,知识库中将要表示的最具体项是什么?回到我们在第 3 节第 1 步中确定的能力问题,构成这些问题答案的最具体概念是知识库中个体实例的良好候选项。
个体实例是知识库中表示的最具体概念。
例如,如果我们只讨论将葡萄酒与食物搭配,我们不会对具体的葡萄酒瓶感兴趣。因此,像 Sterling Vineyards Merlot 这样的术语可能是我们使用的最具体术语。换句话说,Wine 类不是单个葡萄酒瓶的集合,而是由特定酒厂生产的特定葡萄酒的集合。因此,Sterling Vineyards Merlot 将是知识库中的一个实例。
另一方面,如果我们希望在餐厅中维护葡萄酒库存,同时建立一个关于葡萄酒与食物搭配的知识库,那么每瓶葡萄酒可能成为知识库中的个体实例。
类似地,如果我们希望记录 Sterling Vineyards Merlot 每个特定年份的不同属性,那么特定年份的葡萄酒是知识库中的一个实例,而 Sterling Vineyards Merlot 是一个类,包含其所有年份的实例。
另一个规则可以将某些个体实例“移动”到类的集合中:
如果概念形成自然层次结构,那么我们应该将它们表示为类。
考虑葡萄酒产区。最初,我们可能将主要葡萄酒产区(例如法国、美国、德国等)定义为类,并将这些大产区内的具体葡萄酒产区定义为实例。例如,Bourgogne 产区是法国产区类的一个实例。然而,我们还希望表示 Cotes d’Or 产区是 Bourgogne 产区的一部分。因此,Bourgogne 产区必须是一个类(以便拥有子类或实例)。然而,将 Bourgogne 产区定义为一个类,而将 Cotes d’Or 产区定义为 Bourgogne 产区的一个实例似乎是任意的:很难清楚地区分哪些产区是类,哪些是实例。因此,我们将所有葡萄酒产区定义为类。Protégé-2000 允许用户将某些类指定为抽象类,表示该类不能有任何直接实例。在我们的例子中,所有产区类都是抽象类(图 8)。
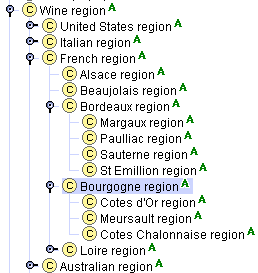
图 8. 葡萄酒产区的层次结构。类名旁边的 "A" 图标表示这些类是抽象类,不能有任何直接实例。
如果我们省略类名中的“产区”一词,那么同样的类层次结构将是错误的。我们不能说 Alsace 类是 France 类的子类:Alsace 不是 France 的一种。然而,Alsace 产区是法国产区的一种。
只有类可以被组织成层次结构——知识表示系统没有子实例的概念。因此,如果术语之间存在自然的层次关系,例如在第 4.2 节中的术语层次结构,我们应该将这些术语定义为类,即使它们可能没有自己的实例。
4.7 限制范围
关于定义类层次结构的最后一点说明,以下规则集在决定本体定义是否完整时总是有帮助的:
本体不应包含领域中的所有可能信息:您不需要比应用所需的程度更进一步地进行专门化(或泛化)(最多每个方向额外一级)。
对于我们的葡萄酒和食物示例,我们不需要知道标签使用了什么纸张,也不需要知道如何烹饪虾类菜肴。
同样,本体不应包含层次结构中类的所有可能属性和区分。
在我们的本体中,我们当然没有包括葡萄酒或食物可能具有的所有属性。我们仅表示了本体中各类项的最显著属性。尽管葡萄酒书籍可能会告诉我们葡萄的大小,但我们并未包含这些知识。同样,我们也没有添加所有可能想象的术语之间的关系。例如,我们没有在本体中包含“最喜欢的葡萄酒”和“最喜欢的食物”这样的关系,仅仅是为了更完整地表示我们定义的术语之间的所有关联。
最后一条规则也适用于在本体中已经包含的概念之间建立关系。考虑一个描述生物学实验的本体。该本体可能包含一个“生物体”的概念。它还可能包含一个“实验者”概念(包括他的名字、所属机构等)。确实,实验者作为一个人,也恰好是一个生物体。然而,我们可能不应该在本体中纳入这一区分:对于这种表示的目的来说,实验者不是一个生物体,我们可能永远不会对实验者本身进行实验。如果我们试图表示本体中类的所有可能信息,“实验者”将成为“生物体”的子类。然而,我们不需要为可预见的应用包含这些知识。事实上,为现有类添加这种额外分类实际上是有害的:现在“实验者”的实例将拥有关于生物体的体重、年龄、物种等数据槽位,但这些数据在描述实验的上下文中完全无关。然而,我们应该在文档中记录这样的设计决策,以便那些查看本体的用户能够受益,他们可能不了解我们设计时的应用背景。否则,打算将本体用于其他应用的人可能会尝试将“实验者”用作“人”的子类,而不知道原始建模并未包含这一事实。
4.8 不相交的子类
许多系统允许我们明确指定多个类是不相交的。类之间不相交意味着它们不能有任何共同的实例。例如,在我们的本体中,甜酒(Dessert wine)类和白葡萄酒(White wine)类不是不相交的:有许多酒同时是这两个类的实例。甜雷司令(Sweet Riesling)类中的 Rothermel Trockenbeerenauslese Riesling 实例就是一个例子。同时,红葡萄酒(Red wine)类和白葡萄酒(White wine)类是不相交的:没有酒可以同时是红葡萄酒和白葡萄酒。指定类之间的不相交关系可以使系统更好地验证本体。如果我们声明红葡萄酒类和白葡萄酒类是不相交的,并且后来创建了一个同时是雷司令(Riesling,白葡萄酒的子类)和波特酒(Port,红葡萄酒的子类)子类的类,系统就可以指出这是一个建模错误。
5 定义属性——更多细节
在本节中,我们将讨论定义本体中的插槽时需要注意的几个细节(第 3 节中的步骤 5 和步骤 6)。主要内容包括反向插槽和插槽的默认值。
5.1 反向槽位
一个槽位的值可能依赖于另一个槽位的值。例如,如果某种葡萄酒由某个酒庄生产,那么该酒庄生产该葡萄酒。这两种关系,maker 和 produces,被称为反向关系。以“双向”存储信息是冗余的。当我们知道某种葡萄酒由某个酒庄生产时,使用知识库的应用程序总是可以推断出反向关系的值,即该酒庄生产该葡萄酒。然而,从知识获取的角度来看,显式地提供这两条信息是方便的。这种方法允许用户在一种情况下填写葡萄酒信息,在另一种情况下填写酒庄信息。知识获取系统随后可以自动填充反向关系的值,从而确保知识库的一致性。
我们的示例中有一对反向槽位:Wine 类的 maker 槽位和 Winery 类的 produces 槽位。当用户创建 Wine 类的一个实例并填写 maker 槽位的值时,系统会自动将新创建的实例添加到对应 Winery 实例的 produces 槽位中。例如,当我们说 Sterling Merlot 是由 Sterling Vineyard 酒庄生产时,系统会自动将 Sterling Merlot 添加到 Sterling Vineyard 酒庄生产的葡萄酒列表中。(图 9)。
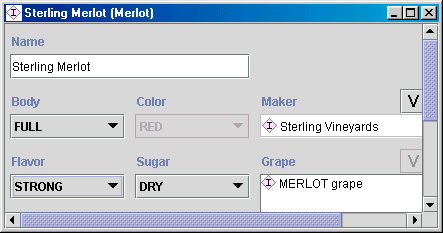
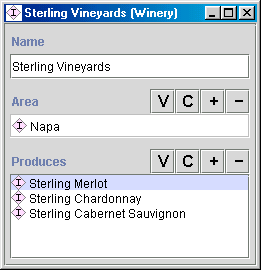
图 9. 带有反向槽位的实例。Winery 类的** produces 槽位是 Wine 类的 maker **槽位的反向关系。填写其中一个槽位会触发另一个槽位的自动更新。
5.2 默认值

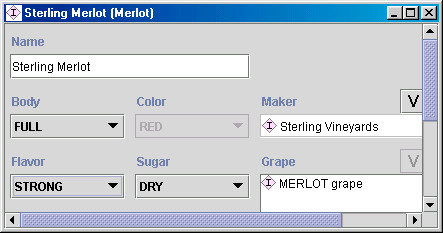
许多基于框架的系统允许为插槽指定默认值。如果某个插槽的值对于一个类的大多数实例来说是相同的,我们可以将该值定义为该插槽的默认值。然后,当创建包含该插槽的类的新实例时,系统会自动填充默认值。我们可以将该值更改为任何其他符合插槽约束的值。也就是说,默认值是为了方便而存在的:它们不会对模型施加任何新的限制,也不会以任何方式改变模型。
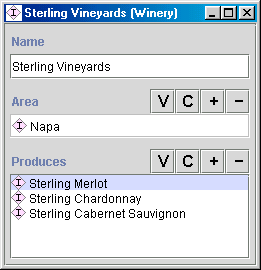
例如,如果我们讨论的大多数葡萄酒都是醇厚型的,我们可以将“醇厚”作为葡萄酒酒体的默认值。那么,除非另有说明,我们定义的所有葡萄酒都将是醇厚型的。
请注意,这与插槽值不同。插槽值是不可更改的。例如,我们可以说甜点酒类的插槽“糖分”的值是“甜”。那么甜点酒类的所有子类和实例的插槽“糖分”都将具有“甜”的值。这个值在类的任何子类或实例中都不能更改。
6 名字的意义
为本体中的概念定义命名约定并严格遵守这些约定,不仅可以使本体更易于理解,还能帮助避免一些常见的建模错误。在命名概念时有许多选择。通常没有特别的理由选择某一种方式。然而,我们需要:
为类和插槽定义命名约定并遵守它。
知识表示系统的以下特性会影响命名约定的选择:
- 系统是否为类、插槽和实例使用相同的命名空间?也就是说,系统是否允许类和插槽使用相同的名称(例如类“酒厂”和插槽“酒厂”)?
- 系统是否区分大小写?也就是说,系统是否将仅大小写不同的名称视为不同的名称(例如“Winery”和“winery”)?
- 系统允许名称中使用哪些分隔符?也就是说,名称中是否可以包含空格、逗号、星号等?
例如,Protégé-2000为其所有框架维护单一命名空间,并且区分大小写。因此,我们不能同时有一个类“winery”和一个插槽“winery”。然而,我们可以有一个类“Winery”(注意首字母大写)和一个插槽“winery”。另一方面,CLASSIC不区分大小写,并为类、插槽和个体维护不同的命名空间。因此,从系统的角度来看,同时命名一个类和一个插槽为“Winery”是没有问题的。
6.1 大写和分隔符
首先,如果对概念名称使用一致的大写规则,可以显著提高本体的可读性。例如,通常会将类名首字母大写,而槽名使用小写(假设系统区分大小写)。
当一个概念名称包含多个单词(例如 Meal course)时,我们需要对这些单词进行分隔。以下是一些可能的选择:
- 使用空格:Meal course(许多系统,包括 Protégé,允许在概念名称中使用空格)。
- 将单词连写并将每个新单词首字母大写:MealCourse。
- 在名称中使用下划线、连字符或其他分隔符:Meal_Course、Meal_course、Meal-Course、Meal-course。(如果使用分隔符,还需要决定是否对每个新单词进行首字母大写处理)
如果知识表示系统允许在名称中使用空格,对于许多本体开发者来说,这可能是最直观的解决方案。然而,重要的是要考虑与您的系统可能交互的其他系统。如果这些系统不使用空格,或者您的展示媒介无法很好地处理空格,那么使用其他方法可能会更为实用。
6.2 单数或复数
一个类名表示一组对象。例如,类 Wine 实际上代表所有的酒。因此,对于某些设计者来说,将类命名为 Wines 而不是 Wine 可能会显得更自然。两种选择没有绝对的优劣之分(尽管在实践中类名通常使用单数形式)。然而,无论选择哪种形式,都应在整个本体中保持一致。一些系统甚至要求用户提前声明是否使用单数或复数形式作为概念名称,并且不允许偏离这一选择。
始终使用相同的形式还可以防止设计者犯下诸如创建一个名为 Wines 的类,然后再创建一个名为 Wine 的子类这样的建模错误(参见第 4.1 节)。
6.3 前缀和后缀命名规范
一些知识库方法建议在命名中使用前缀和后缀规范,以区分类和槽(slots)。两种常见的做法是为槽名称添加前缀“has-”或后缀“-of”。因此,如果我们选择“has-”规范,槽名称将变为 has-maker 和 has-winery。如果我们选择“of-”规范,槽名称将变为 maker-of 和 winery-of。这种方法使得任何人只需查看术语即可立即判断该术语是类还是槽。然而,这种命名方式会使术语名称稍微变长一些。
6.4 其他命名注意事项
以下是定义命名约定时需要考虑的几点:
- 不要在概念名称中添加诸如“class”(类)、“property”(属性)、“slot”(槽)等字符串。从上下文中总是可以清楚地判断概念是类还是槽。例如,如果为类和槽使用不同的命名约定(比如类名使用大写,而槽名不使用大写),名称本身就能表明概念的类型。
- 通常最好避免在概念名称中使用缩写(例如,使用 Cabernet Sauvignon 而不是 Cab)。
- 类的直接子类名称应统一包含或统一不包含父类的名称。例如,如果我们为 Wine 类创建两个子类来表示红酒和白酒,这两个子类的名称应该是 Red Wine 和 White Wine 或 Red 和 White,而不是 Red Wine 和 White。
7 其他资源
我们在示例中使用了 Protégé-2000 作为本体开发环境。Duineveld 和同事(Duineveld 等,2000)描述并比较了许多其他本体开发环境。
我们尝试介绍本体开发的基础知识,但并未讨论许多高级主题或替代的本体开发方法论。Gómez-Pérez(Gómez-Pérez,1998)和 Uschold(Uschold 和 Gruninger,1996)提出了替代的本体开发方法论。Ontolingua 教程(Farquhar,1997)讨论了知识建模的一些形式化方面。
目前,研究人员不仅强调本体开发,还强调本体分析。随着更多本体被生成和重用,将会有更多工具可用于分析本体。例如,Chimaera(McGuinness 等,2000)提供了用于分析本体的诊断工具。Chimaera 执行的分析包括检查本体的逻辑正确性以及诊断常见的本体设计错误。本体设计者可能希望在不断发展的本体上运行 Chimaera 诊断,以确定其是否符合常见的本体建模实践。
8 结论
在本指南中,我们描述了一种用于声明性基于框架系统的本体开发方法。我们列出了本体开发过程中的步骤,并讨论了定义类层次结构以及类和实例属性的复杂问题。然而,即使遵循所有规则和建议,最重要的一点仍需牢记:对于任何领域来说,都不存在唯一正确的本体。本体设计是一个创造性的过程,由不同的人设计的本体不会完全相同。本体的潜在应用以及设计者对领域的理解和观点无疑会影响本体设计的选择。“实践出真知”——我们只能通过在为其设计的应用中使用本体来评估其质量。
致谢
Protégé-2000 (http://protege.stanford.edu) 由斯坦福医学信息学的 Mark Musen 团队开发。我们使用 Protégé-2000 的 OntoViz 插件生成了一些图示。我们从 Ontolingua 本体库 (http://www.ksl.stanford.edu/software/ontolingua/) 导入了初始版本的葡萄酒本体,该本体库使用了由 Brachman 和同事(Brachman et al. 1991)发布并与 CLASSIC 知识表示系统一起分发的一个版本。随后,我们对本体进行了修改,以展示声明式基于框架的本体的概念建模原则。Ray Fergerson 和 Mor Peleg 对早期草稿的广泛评论极大地改进了本文。
参考文献
Booch, G., Rumbaugh, J. 和 Jacobson, I. (1997). The Unified Modeling Language user guide: Addison-Wesley.
Brachman, R.J., McGuinness, D.L., Patel-Schneider, P.F., Resnick, L.A. 和 Borgida, A. (1991). Living with CLASSIC: When and how to use KL-ONE-like language. Principles of Semantic Networks. J. F. Sowa, editor, Morgan Kaufmann**:** 401-456.
Brickley, D. 和 Guha, R.V. (1999). Resource Description Framework (RDF) Schema Specification. Proposed Recommendation, World Wide Web Consortium**:** http://www.w3.org/TR/PR-rdf-schema.
Chimaera (2000). Chimaera Ontology Environment. www.ksl.stanford.edu/software/chimaera
Duineveld, A.J., Stoter, R., Weiden, M.R., Kenepa, B. 和 Benjamins, V.R. (2000). WonderTools? A comparative study of ontological engineering tools. International Journal of Human-Computer Studies 52(6): 1111-1133.
Farquhar, A. (1997). Ontolingua tutorial. http://ksl-web.stanford.edu/people/axf/tutorial.pdf
Gómez-Pérez, A. (1998). Knowledge sharing and reuse. Handbook of Applied Expert Systems. Liebowitz, editor, CRC Press.
Gruber, T.R. (1993). A Translation Approach to Portable Ontology Specification. Knowledge Acquisition 5: 199-220.
Gruninger, M. 和 Fox, M.S. (1995). Methodology for the Design and Evaluation of Ontologies. In: Proceedings of the Workshop on Basic Ontological Issues in Knowledge Sharing, IJCAI-95, Montreal.
Hendler, J. 和 McGuinness, D.L. (2000). The DARPA Agent Markup Language. IEEE Intelligent Systems 16(6): 67-73.
Humphreys, B.L. 和 Lindberg, D.A.B. (1993). The UMLS project: making the conceptual connection between users and the information they need. Bulletin of the Medical Library Association 81(2): 170.
McGuinness, D.L., Abrahams, M.K., Resnick, L.A., Patel-Schneider, P.F., Thomason, R.H., Cavalli-Sforza, V. 和 Conati, C. (1994). Classic Knowledge Representation System Tutorial. http://www.bell-labs.com/project/classic/papers/ClassTut/ClassTut.html
McGuinness, D.L., Fikes, R., Rice, J. 和 Wilder, S. (2000). An Environment for Merging and Testing Large Ontologies. Principles of Knowledge Representation and Reasoning: Proceedings of the Seventh International Conference (KR2000). A. G. Cohn, F. Giunchiglia 和 B. Selman, editors. San Francisco, CA, Morgan Kaufmann Publishers.
McGuinness, D.L. 和 Wright, J. (1998). Conceptual Modeling for Configuration: A Description Logic-based Approach. Artificial Intelligence for Engineering Design, Analysis, and Manufacturing - special issue on Configuration.
Musen, M.A. (1992). Dimensions of knowledge sharing and reuse. Computers and Biomedical Research 25: 435-467.
Ontolingua (1997). Ontolingua System Reference Manual. http://www-ksl-svc.stanford.edu:5915/doc/frame-editor/index.html
Price, C. 和 Spackman, K. (2000). SNOMED clinical terms. BJHC&IM-British Journal of Healthcare Computing & Information Management 17(3): 27-31.
Protege (2000). The Protege Project. http://protege.stanford.edu
Rosch, E. (1978). Principles of Categorization. Cognition and Categorization. R. E. 和 B. B. Lloyd, editors. Hillside, NJ, Lawrence Erlbaum Publishers**:** 27-48.
Rothenfluh, T.R., Gennari, J.H., Eriksson, H., Puerta, A.R., Tu, S.W. 和 Musen, M.A. (1996). Reusable ontologies, knowledge-acquisition tools, and performance systems: PROTÉGÉ-II solutions to Sisyphus-2. International Journal of Human-Computer Studies 44: 303-332.
Rumbaugh, J., Blaha, M., Premerlani, W., Eddy, F. 和 Lorensen, W. (1991). Object-oriented modeling and design. Englewood Cliffs, New Jersey: Prentice Hall.
Uschold, M. 和 Gruninger, M. (1996). Ontologies: Principles, Methods and Applications. Knowledge Engineering Review 11(2).